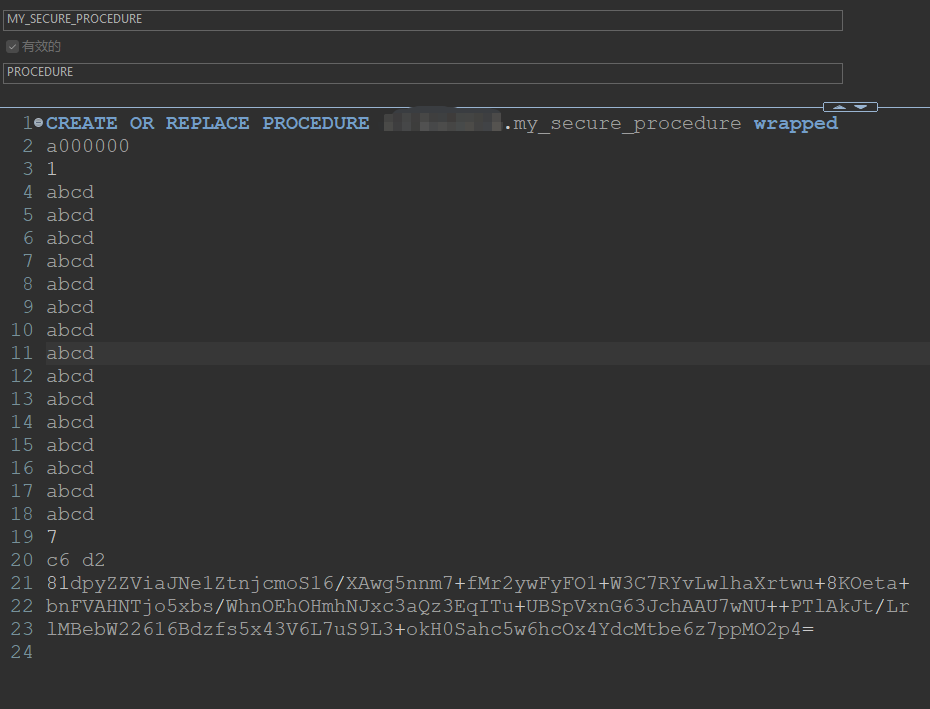
准备需加密的sql源码文件
本例以加密存储过程源码为例,sql如下,存储过程名为 my_secure_procedure:
sql
CREATE OR REPLACE PROCEDURE my_secure_procedure IS
BEGIN
DBMS_OUTPUT.PUT_LINE('This is a secure procedure.');
END;
/使用 wrap 工具加密 SQL 文件
在命令行中输入以下命令,将 SQL 文件加密为 PLB 文件:
cmd
wrap iname=原文件路径.sql oname=加密后文件路径.plb示例:
cmd
wrap iname=D:\sql\my_secure_procedure.sql oname=D:\sql\my_secure_procedure.plb加密成功提示
若出现以下提示,则表示加密成功:
登录到 SQL*Plus
在命令行中继续输入以下命令登录到 Oracle 服务器:
cmd
sqlplus 用户名/密码@数据库实例示例:
cmd
sqlplus scott/tiger@orcl执行加密后的 PLB 文件创建存储过程
在 SQL*Plus 中执行以下命令(注:登录到sqlplus 时需要在plb所在目录登录sqlplus ,不然下面这个语句不一定能找到加密后的sql文件):
sql
@my_secure_procedure.plb执行存储过程
使用 EXEC 命令执行存储过程:
sql
EXEC my_secure_procedure;输出结果:
text
This is a secure procedure.查看加密后的存储过程
通过 Oracle 管理工具(如 Dbeaver)登录后,可以执行该存储过程,但查看源码时只能看到加密后的代码: